












※ (上)편을 보고 오시는 것을 추천드립니다.바로가기
딥러닝은 ‘깊은’ 신경망을 사용하는 인공지능 기술의 한 종류다. ‘깊은’이라는 단어를 강조한 이유는 신경망이 깊어질수록 학습을 위한 계산량이 기하급수적으로 증가하기 때문이다. 아래 그림은 8차원의 입력을 받아 4차원의 결과를 출력하는 3층 신경망을 나타내며, 중간의 히든 레이어(Hidden Layer)들은 9개의 노드(동그라미)로 구성되어 있다. 아래 그림을 보면 동그라미 사이에 수많은 선들을 볼 수 있는데, 이러한 선들이 학습을 통해 갱신해야 하는 변수다. 즉 아래 그림에서 갱신해야하는 변수의 개수는 8 x 9 x 9 x 9 x 4로 23,328개이다.
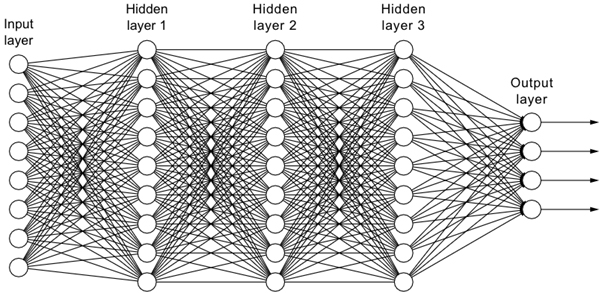
고전적인 기계학습 관점에서 100개의 노드로 구성된 히든레이어(Hidden Layer)로 3층 신경망을 위 그림과 동일하게 구성하였다면, 변수의 개수는 8 x 100 x 100 x 100 x 4로 32,000,000개가 된다. 이는 결코 적은 숫자가 아니며, 불과 15년 전만 해도 이 정도 크기의 신경망을 쉽게 학습할 수 있는 방법이 없었다.
GPU 제조 회사인 엔비디아(NVIDIA)가 병렬처리 전용 응용 프로그래밍 인터페이스(API)인 쿠다(CUDA)를 발표한지 정확히 5년 후, 캐나다 토론토대학교 제프리 힌튼(Geoffrey Hinton) 교수 연구실의 알렉스 크리제브스키(Alex Krizhevsky)와 일리아 수츠케버(Ilya Sutskever)가 엔비디아의 GTX 580 GPU 2개를 이용해 신경망을 학습하는 알렉스넷(AlexNet)을 개발했다. 개발팀이 알렉스넷을 가지고 영상 분류 대회인 ILSVRC에서 우승하면서 엔비디아 GPU에 대한 수요는 폭발적으로 증가하기 시작했다. 참고로 알렉스넷을 개발한 일리야 수츠케버는 현재 오픈AI에서 ChatGPT 개발을 주도한 인물이다.
알렉스넷 이후 신경망 학습에 필수적인 하드웨어로 자리 잡은 GPU는 비슷한 시기에 기술 발전을 이루던 클라우드 컴퓨팅 기술에 접목되기 시작했다. 하지만 고성능 GPU를 탑재한 서버들을 관리하는 것은 여러모로 쉬운 일은 아니었으며, 특히 인공지능 분야 연구자들은 이러한 서버를 직접 관리하는 것에 많은 어려움을 느끼고 있었다. 클라우드 컴퓨팅은 가상화 기술과 네트워크를 통해 온디맨드(On-demand) 계산 자원을 활용하게 해주었는데, 여기에 GPU 자원을 추가하면서 인공지능 연구자는 인터넷만 연결되어 있으면 GPU 자원이 할당된 고성능 서버를 어디서나 활용할 수 있었다. 하지만 GPU 자원은 매우 비싸기 때문에 이를 적극적으로 활용하는 사용자는 소수에 불과했고, 빅테크들은 주로 자체 서비스 및 기술 개발을 위한 목적으로 GPU 클라우드를 활용하고 있었다.
이러한 상황에서 2023년 ChatGPT의 등장은 GPU 클라우드 사용을 선택이 아닌 ‘필수’로 바꿔놓았다. 현재 거대언어모델은 수 천대의 GPU를 한 달 가까이 동시에 사용해야 기초 모델(Foundation Model)을 학습할 수 있다. 거대언어모델을 개발하는 기업들 입장에서 이만한 숫자의 GPU를 사용할 수 있는 곳은 아마존, 마이크로소프트, 구글 등 주요 클라우드 업체뿐이며, 엔비디아는 이러한 클라우드 업체에 고성능 GPU를 공급하는 유일한 기업이라고 볼 수 있다. 현재 많은 기업에서 인공지능 전용 칩을 개발하려는 이유도 엔비디아에 종속된 환경에서 벗어나기 위한 방편으로 볼 수 있다. 얼마 전 공개된 엔비디아 H100 80GB GPU는 개당 가격이 6천만 원을 상회함에도 구하기가 쉽지 않은 상황이며, 한동안 이러한 특수 목적의 계산 자원에 대한 수요가 증가할 것으로 예상된다.
이번 칼럼에서는 전편에 이어서 GPU, 클라우드 컴퓨팅, 그리고 ChatGPT를 포함한 인공지능 기술과의 관련성에 대해 설명하였다. 오픈AI가 마이크로소프트에서 투자 받은 12조 원을 마이크로소프트 애저 클라우드의 GPU 학습에 상당 부분 사용하였으며, 마이크로소프트 애저 클라우드의 GPU 대다수는 엔비디아의 GPU로 구성되어 있다. 즉 재주는 오픈AI가 부리고 돈은 엔비디아가 번다고 할 수 있다.

빅데이터연구센터
전태준 특수전문학자
전태준 특수전문학자는 2019년에 입사해 아산생명과학연구원 빅데이터연구센터 특수전문학자로 근무하고 있습니다. 의료 인공지능을 주제로 한국과학기술원(KAIST) 전산학과 박사를 졸업하였습니다. 현재 빅데이터연구센터 전산정보의학연구단을 이끌고 있으며, 인공지능 기술의 의료 분야 접목에 관심이 많습니다.
